Capturing from vast, analyzing for the best
C&T’s VITOVA EIM releases new information recognition module – VitalCapture
The data lying in raw was just data until yesterday. The process of extracting data accurately is the way to start the journey of Big Data. Among different data sources, paper is an inescapable part of information flow-in. Automated processing of fixed forms such as application forms, personal records or ballot papers with Optical character recognition (OCR) is widely accepted. But what about processing of other types of documents? Forms without a fixed layout, like invoices, receipts, legal documents, etc.?
In response to the need of capturing, C&T’s flagship software product – VITOVA EIM has released the latest module – VitalCapture, a comprehensive data capture solution, which turns vast information into business-ready data and delivers not only to VitalDoc Document Management System but also other third-party systems and information repositories.
VitalCapture technologies are based on the principles of Integrity, Purposefulness and Adaptability (IPA) which imitate the way humans recognize objects. The operation process is defined into 5 stages: Capture, Classification, Recognition, Store and Integration.
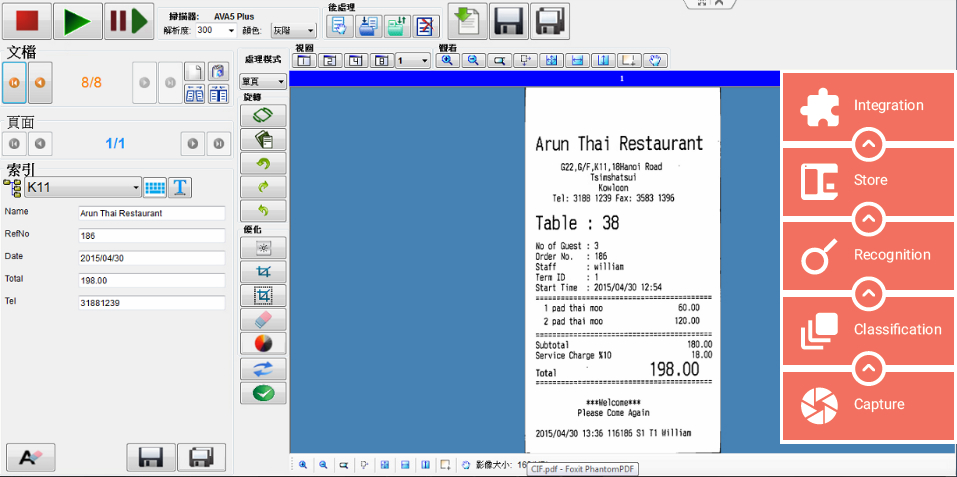
Following the IPA principal, the geometrical and spatial characteristics of a document (e.g. dining receipt) are collected by pre-defined fields. VitalCapture allows intelligent and flexible approach to data extraction: content of the field, relation of other objects, the size of the filed, lines or gaps nearby. The new module works well even if it has to deal with documents of poor quality which cannot be recognized by other OCR engines.
The latest module of VITOVA EIM paths the way to new generation of Enterprise Information Management, starting from capturing and move forward to process and share. VitalCapture empowers enterprise clients to uplift their readiness to harvest from streamlining information processing as well as information analysis.